

Автор: Цветелина Николова
Компресиране на данни
[2]Архивирането или компресирането на данни е процес, при който даден файл, се реформира във формат ZIP или RAR. По този начин се създават негови резервни копия. Разликата с оригиналния файл е, че новият заема по-малко място, защото се компресира. За да се осъществи този процес, се прилагат различни математически методи и алгоритми, чрез които се съпоставят различни кодове, махат се излишни знаци.
[3]Компресирането представлява кодиране на информацията, използвайки по–малко битове от оригиналния файл. Компресирането може да бъде със или без загуба. Компресирането без загуба намалява броя на битовете, като идентифицира и елиминира статистически излишните. Няма загуба на информация. При компресирането със загуба се идентифицира ненужната информация и се премахва. По този начин се намалява броят на битовете. Процесът на намаляване на размера на файла често се нарича компресиране на данни, но всъщност формалното му име е Кодиране на сорс кода. Компресирането е полезно, защото спомага да се намалят ресурсите, използвани за складиране или пренасяне на информацията. Компресираната информация трябва да бъде декомпресирана, за да бъде използвана. Този допълнителен процес изисква допълнително изчислително време, което расте пропорционално на размера на компресирания файл. При създаването на схеми за компресиране на данни се налага да се правят компромиси, включващи степента на компресия и изчислителните ресурси необходими, за да се компресира файлът.
[3]Компресирането на данни е едно от основните проявления на теорията на информацията. Тя е клон на математиката, водеща началото си от работата на Клод Шенън в Bell Labs през втората половина на 40-те години, където той разглежда различни въпроси, свързани с информацията като метод на възникване, съхраняване и предаване. Компресирането на данните е част от Теорията на информацията, тъй като се занимава с излишеството на информация в дадено съобщение. Излишната информация в едно съобщение ни принуждава да използваме повече битове за неговото кодиране. Ако може да се премахне излишеството, ще се намали размерът на съобщението. Теорията на информацията използва термина ентропия като мярка колко информация е закодирана в дадено съобщение. Колкото е по-висока ентропията на дадено съобщение, толкова по-голямо е информационното му съдържание. Ентропията на дадено съобщение се дефинира като отрицателен логаритъм при основа две. Ентропията на цялото съобщение е сумата от ентропиите на всички символи в съобщението.
Първите разработки са направени много преди възникването на съвременния компютър, затова идеята за създаването на алгоритми, базирани на двоичната бройна система е огромен скок в науката. За да се измери нивото на компресията, трябва всички алгоритми да се поставят в еднакви условия. Те компресират един едни и същи файлове, които се разделят на три големи групи:
- Текст – бележки, ръкописи, програмен код и друга текстова информация.
- Двоични данни – таблици, изпълними файлове, бази данни.
- Графична информация.
Ползи от архивирането
– намаляване на заетото пространство, и съответно на компютъра може да се запише далеч повече информация, отколкото ако ненужните файлове не са архивирани;
– повечето от архивираните файлове остават незасегнати от компютърни вируси. Това е оптималния вариант за запазване им;
– обикновено пощите и програмите за комуникация имат ограничение върху обема на файла. Затова архивирането може да разреши преноса на един филм, който иначе няма как да бъде изпратен;
Компресия на данни без загуба
[2]Алгоритмите за компресиране без загуба обикновено използват методи, за премахване на статистическото повторение, за да представят данните в по – сбит вариант, без да се губи информация. Компресирането без загуба е възможно, тъй като в повечето данни от реалния живот има статистическо излишество. Например в едно изображение може да има области, в които цветът не се променя върху няколко пиксела, вместо да кодираме „червен пиксел, червен пиксел, …”, информацията може да се представи като „279 червени пиксела”. Това е базов пример за това как работи run-length encoding, има много схеми, по които може да се намали размер на файл, като се елиминира излишеството в информацията.
Най-добрите модерни методи за компресия без загуба използват вероятностни модели, такива като прогнозирането по частично съвпадение.
Класовете от граматично-базирани кодове набират популярност, защото те могат да компресират изключително добре многократно повтарящи се текстове, например колекция от биологични данни за едни и същи или родствени видове, документ с огромен набор от версии, интернет архиви и т.н. Основна задача на граматичното кодиране е изграждането на контекстно независима граматика произтичаща от единствен низ. Sequitur и Re-Pair са практични граматични алгоритми за компресия, за които има достъпни публични кодове.
Като резултат от усъвършенстване на тези техники, статистическите прогнозирания могат да бъдат комбинирани в алгоритъм наречен аритметично кодиране. Аритметичното кодиране, измислено от Jorma Rissanen и превърнато в практичен метод от Witten, Neal и Cleavy, постига по-добра компресия от добре известния алгоритъм на Huffman и се справя на изключително ниво при задачи за адаптивна компресия на данни, където прогнозиранията са контекстно-зависими. Аритметичното кодиране се използва в bi-level стандарта за компресията на изображения JBIG и при стандарта за компресия на документи DjVu. Системата за вход на текст Dasher използва инвертиран аритметичен кодер.
Файлови формати
[1]RAR е архивен файлов формат, който поддържа компресиране на данни, възстановяване на грешки и раздробяване на файлове. Разработен е от руският софтуерен инженер Евгени Рошал. Името RAR идва от Roshal ARchive и в момента се поддържа от win.rar GmbH.
Файловото разширение използвано от RAR e .rar за обем данни и .rev за файлови набори за възстановяване. Предходните версии на RAR разделят големите файлови архиви на няколко по – малки. Добавят се числа в разширенията на малките части, за да могат те да са правилно подредени. Първият от малките файлове е с разширение .rar, вторият – .r00, после r.01, r.02 и т.н. Минималния размер на RAR файл е 20 байта, а максималния – is 9,223,372,036,854,775,807 байта, което е 8 екзабайта минус 1 байт.
RAR файлове се създават с WinRAR, RAR, или всеки друг софтуер, който е под лиценз на Александър Рошал, по – възрастния брат на Евгени Рошал, а могат да бъдат разархивирани с много на брой програми. RARLAB предоставят сорс код за безплатна програма за разархивиране, макар че самия код е под платен лиценз. Тази програма може да разархивира .rar файлове, но не може да създава такива.
[1]ZIP е популярен формат за компресиране на данни и архивиране на файлове. Файл в този формат обикновено има разширение .zip и съхранява в компресиран или некомпресиран вид един или няколко файла, които могат да се извличат от него, посредством разопаковане със специална помощна програма. ZIP е разработен от Филип Кац за употреба в програмата PKZIP. Впоследствие се появяват много други инструменти, работещи с този формат.
[1]7z е компресиран архивен файлов формат, който поддържа няколко различни алгоритъма за компресиране на данни, криптиране и препроцесиране. 7z форматът първоначално се появява при програмата за архивиране 7-Zip. Тази програма е публично достъпна под лиценза GNU Lesser General Public License.
Официалната спецификация на 7z файловия формат се разпределя при сорс кода на 7-Zip. Спецификацията може да бъде намерена в простия .doc текстови формат на субдиректорията, намираща се в дистрибуцията на сорс код.
Някои алгоритми за компресия на данни без загуба
Методна Шенън-Фано
[4]Методът изисква да са известни вероятностите за срещането на всеки един символ в съобщението. На базата на тези вероятности се конструира таблица със следните характеристики:
– всеки символ се представя чрез код
– различните кодове имат различен брой битове
– кодовете за символи с по-ниска вероятност имат повече битове от тези с по-висока вероятност
– кодовете могат еднозначно да бъдат декодирани в символи
При алгоритъма на Шенън-Фано има един основен проблем – в случай на почти равно разделяне на групите по вероятности е възможно да възникнат две възможности, за конструиране на таблицата, което води до пораждане на различни дървета.
Метод на Хъфман
[4]Алгоритъмът на Хъфман е сравнително прост, но универсален алгоритъм за компресия без загуба на данни. При него се предполага, че е даден краен поток от числа в някакъв предварително фиксиран интервал (информацията е поредица от байтове). Алгоритъмът себазира на идеята, че найчесто срещаните символи в поредицата трябва да се записват с наймалък брой битове. Така сесъставя нова азбука, която следва тази идея и след това превеждаинформацията в новата азбука.
Кодирането е обратимо – кодираната последователност можеда се декомпресира и по този начин да се намери първоначалната поредица.
[4]При този метод се заменя целият входен поток с едно единствено дробно число. Всъщност идеята е много стара, но нейното прилагане става възможно едва когато се появяват средства за нейното осъществяване – компютри с регистри и фиксиран размер. Резултатът при аритметичното кодиране е едно единствено число, по – малко от едно и по – голямо или равно на нула. Това число дава един единствен резултат при декодирането му и това е потокът от символи, еднакъв на използвания при генерирането на числото. За генериране на числото на всеки символ се съпоставя вероятност.
Прилагане на мощни статистически модели
[4]Хъфмановото и аритметичното кодиране могат да се използват с фиксирани, или адаптивни модели, но при всички случай имат нужда от статистически модел, който да лежи в основата. Използването на статистически модели от първи ред дава доста задоволителни резултати, но комбинирането на някой от методите на кодиране с мощни статистически модели води до повишаване многократно степента на компресия. За да постигнем изобщо някакво ниво на компресия, статистическият модел трябва да отговаря на някои основни изисквания:
- Правилно да предсказва честотите ( вероятностите ) на всички символи от входния поток.
- Генерираните от модела вероятности да се различават от идеалното равномерно разпределение.
Метод за компресия на речници
[4]При речниковите методи кодовете представляват индекси към речник с низове. Ако дължината на използвания код е по-малък от дължината на заместените низове, данните се компресират.
В много отношения речниковият метод е по-лесен за разбиране, тъй като те използват похвати от ежедневието на човека, като телефони номера пощенски кодове и т.н.
RLE
[5]С метода RLE (Run Length Encoding), или кодиране по дължина, се цели намаляване на размера на повтарящи се поредици от знаци. Обикновено RLE използва по 2 байта за представянето на един знак – един за броя повторения и един за самия знак. Може да се използва върху всякакъв тип данни, но коефициентът на компресия ще е различен при различните типове. Обикновено RLE не води до висока компресия, но за сметка на това алгоритъмът е бърз за изпълнение.
LZW
[5]Алгоритъмът LZW (Abraham Lempel, Jakob Ziv и Terry Welch) е без загуба на данни. Използва се най-често в графични файлове, предимно TIFF и GIF. Целта е да се намери заместител на повтарящи се съвкупности от символи. LZW работи на следния принцип: всяка нова съвкупност от символи се запазва в таблица, след което се замества с указателен символ. Например ако имате низ от вида ХХХХХХХХХ, при компресиране ще се запише само 9Х, т.е. вместо 9 ще се запишат само 2 бита. LZW алгоритъмът е ефективен само при данни с чести повторения.
Приложение в компютърната графика
GIF (Graphics Interchange Format)
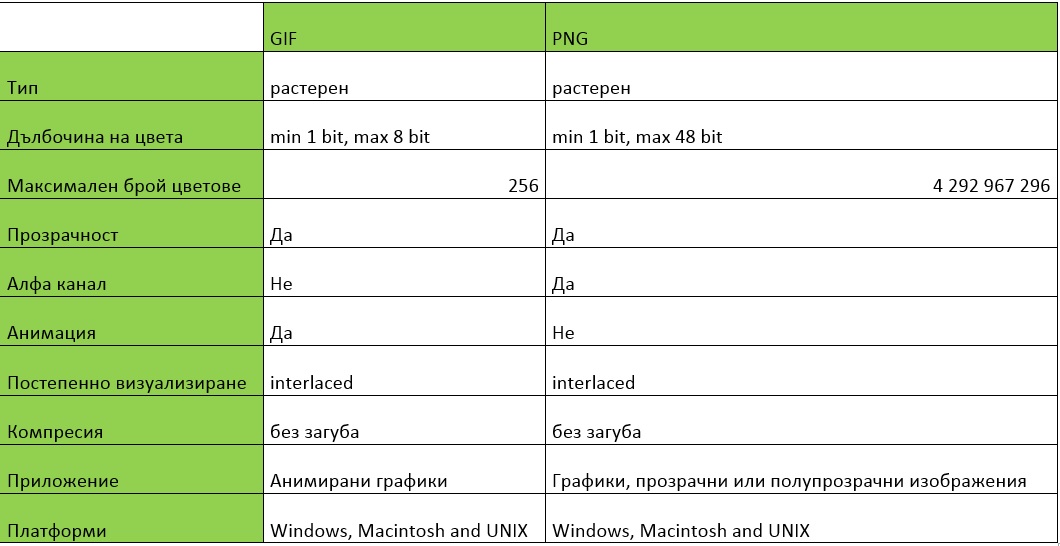
[5][7]Graphics Interchange Format (*.gif) най-често се използва за растерни изображения съставени от контури или сектори от няколко различни цвята. Форматът GIF поддържа 256 (8 бита) или по-малко цветове. В допълнение версия GIF89a поддържа прозрачност, позволяваща даден цвят от изображението да бъде зададен като прозрачен. Тази характеристика прави форматът GIF особено популярен за Web изображения.
Идеята на GIF файловете е да се създаде възможно най-малък графичен файл за upload и download от електронния Bulletin Board Systems (BBS).По този начин се създава високо компресиран формат, който намалява времето за трансфер на файлове по телефонната линия. Компресията се осъществява по LZW метода (LZW method for indexed color tables).
Има две версии на файловият формат GIF: 87a и 89a.
И двете версии дават възможност за използване на метода известен като interlacing – дадено изображение е съхранено използвайки презредово вместо последователно зареждане. Чрез опцията за презредово зареждане (interlaced) на изображения те се показват отначало със силно разредени линии, които постепенно се попълват с нови, докато се получи оригиналното отчетливо и рязко изображение. По този начин потребителят вижда бързо изображение в общи линии, вместо да чака бавното му изграждане ивица по ивица. Повечето комуникационни програми (за BBSs и InterNet) позволяват download на GIF файлове и разглеждането им докато те се download-ват. Ако изображението е interlaced, то може да бъде видяно преди download-а да бъде завършен и ако не е подходящо download-а може да се прекрати. Това пести време и пари при download на изображения.
GIF най-често се използва за презентации на екран. Той поддържа анимация – може да съдържа множество изображения (кадри). Това означава, че може да съхранява няколко изображения в един файл, които при отварянето му се сменят през определен интервал от време. Анимираните изображения трябва да се избягват, когато възнамерявате да разпечатвате страницата.
GIF е най-старият поддържан в Web графичен формат, той се разпознава от всички графични Web браузъри, осигурява добра компресия, но поддържа само 256 цвята. GIF е подходящ за всички Web изображения, но е най- добър за рисунки и илюстрации. Форматът GIF не е подходящ за снимки. В допълнение възможността на GIF да поддържа анимация и прозрачност го прави подходящ за специалните ефекти в Web.
GIF Files могат да поддържат от 2 цвята (монохромен режим) до 256 цвята.
PNG (Portable Network Graphics)
[6]За Web, PNG има три основни предимства пред GIF: алфа канали (променлива прозрачност – поддържа прозрачни области без назъбени контури – функция anti-aliasing; съхранява само един алфа-канал за дефинирането им) гама корекция (междуплатформен контрол на яркостта на изображението) и двумерен interlacing (метод за презредово изграждане на изображението). В почти всички случаи PNG има по-добра компресия от GIF, но в повечето случаи разликата е между 5% до 25%, не достатъчен фактор за потребителите, за да го включат като самостоятелен. Една от характеристиките на GIF, която PNG не поддържа множество изображения и съответно анимацията (multiple-image support, especially animations); PNG е проектиран като формат само за самостоятелни образи (single-image format only).
Форматът PNG е много гъвкав. Дълбочината на цвета може да варира от един единствен бит до 48bit. Най-често използваните компютърни дисплеи и браузери са в състояние да поддържат дълбочина на цвета до 24bit (16,777,216 възможни цветове). Форматът PNG позволява да се добавя алфа-канал от 8bit към RGB. Този алфа-канал добавя прозрачност към изображенията. Прозрачност може да се зададе в 256 стъпки от напълно прозрачно за напълно непрозрачно.
Internet Explorer не е в състояние да поддържа 32bit PNG изображения правилно. Този браузър поддържа пълна прозрачност само при 8bit PNG изображения.
Алфа-канал в PNG графика се използва за контролиране на прозрачността на изображението. Трите 8 bit RGB в допълнение с четвъртият 8bit алфа-канал образуват 32bit изображения. По този начин се позволяват 256 нива на прозрачност.
TIFF (Tagged Image File Format)
[6]TIFF се използва главно за обмен на документи между различни приложения и различни компютърни платформи.Поддържа LZW метод на компресия.
Графичният формат Tagged-Image File Format (TIFF) е стар стандарт с десетки отчасти заменими под-формати. Проектиран, разработен и поддържан първоначално от Aldus (Adobe) с идеята да стане стандартен формат. По тази причина той е предназначен да поддържа само някои възможности. В резултат на този начин на проектиране се осигурява гъвкавост и множество възможности при начина на запазването на изображенията в TIFF формат.
Ето защо няма приложения, които поддържат всички варианти на TIFF формат. Някои професионални приложения поддържат голяма част от вариантите на TIFF, но винаги ще има неясни варианти, които ще създават проблеми на някои приложения.
Между-платформен формат поддържан от Macintosh, Windows, и UNIX.
TIFF не се поддържа в Web. TIFF формата използва 6 различни кодиращи метода:
– No-compression
– Huffman
– Pack Bits
– LZW
– Fax Group 3
– Fax Group 4
Различава 3 различни категории от различните типове изображения:
– Чернобяло (Black and white)
– Сиво (Gray scaled)
– Цветно (Colored)
Сравнение между GIF и PNG
Заключение
Компресията намалява размера на файла. Основно се използва при растерните изображения и по-рядко при векторни изображения. Има два вида компресия:
- компресия без загуба (lossless formats)
- компресия със загуба (lossy formats)
Компресията без загубаизползва алгоритъм запазващ цялата оригинална информация за изображението. При декомпресия изображението се възстановява напълно без загуба на информация. Недостатък е, че процента на компресия е много по-нисък. GIF, TIFFи PNGса формати използващи компресия без загуба.
TIFF (Tagged Image File Format) *.tif – растерен файлов формат, чиито основни приложения са за предпечатна подготовка и обмен на документи между различни приложения и платформи.
GIF (Graphics Interchange Format) *.gif – растерен файлов формат (най-старият файлов формат за Web). Подходящ за изображения без много цветови преходи. Две версии – GIF87a, GIF89a.
PNG(Portable Network Graphics)*.png – поддържа пълна и частична прозрачност – 254 различни нива на частична прозрачност (алфа-канал). Поддържа неограничен брой цветове – 48-битов цвят. Двумерно презредово визуализиране (interlacing) за по-бързо зареждане на файла.Поддържан в Web.
